

In today’s digital world, data is one of the most valuable assets for businesses. Companies rely on data to make informed decisions, improve customer experiences, and optimize operations. However, raw data is often scattered across multiple sources and must go through various stages before it becomes useful. This is where data pipelines come into play. A well-structured data pipeline helps collect, process, and store data efficiently.
If you’re new to data engineering and want to understand data pipelines in a simple way, this guide is for you. We will explain what data pipelines are, why they are important, how they work, the tools used, and the challenges you may face when building them. By the end of this article, you will have a clear understanding of data pipelines and their role in modern data engineering.
What Are Data Pipelines? A Simple Explanation
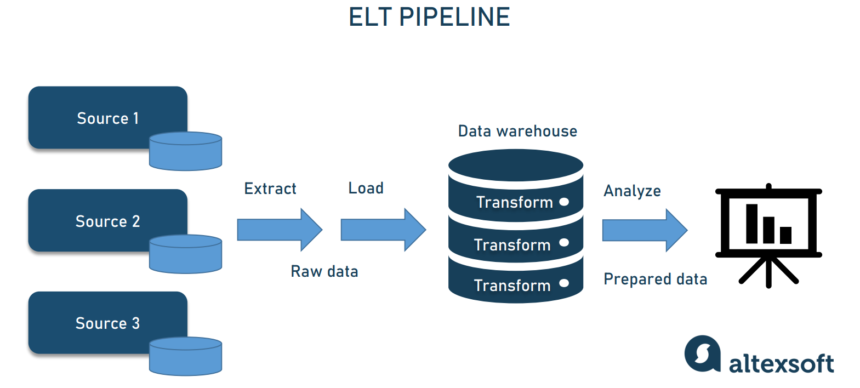
A data pipeline is a series of steps that move data from one place to another while transforming it into a usable format. Think of it as a system of connected pipes where raw data flows in, gets processed, and comes out as structured and meaningful information.
For example, imagine an e-commerce company that collects customer purchase data from its website, payment systems, and warehouses. This raw data needs to be cleaned, analyzed, and stored in a database for reporting. A data pipeline automates this entire process, ensuring that the data is always updated and ready for analysis.
Why Are Data Pipelines Important in Data Engineering?
Data pipelines play a crucial role in modern data engineering because they:
- Automate Data Movement → They ensure that data flows seamlessly from source to destination.
- Improve Data Quality → By filtering and cleaning raw data, they enhance accuracy and reliability.
- Enable Real-time Analytics → Businesses can make fast decisions based on up-to-date information.
- Reduce Manual Effort → Instead of manually handling data, engineers can rely on automated workflows.
- Support Scalability → As data volume grows, pipelines help manage large-scale data efficiently.
Without data pipelines, organizations would struggle with messy, inconsistent, and outdated data, leading to poor business insights.
How Do Data Pipelines Work? Step-by-Step Guide
A data pipeline follows a structured workflow to collect, process, and store data efficiently. Below are the key stages of a data pipeline:
1. Collecting Data
The first step in any data pipeline is data collection. Organizations gather raw data from multiple sources such as:
- Databases (e.g., MySQL, PostgreSQL)
- APIs (e.g., social media APIs, financial APIs)
- Log Files (e.g., server logs, application logs)
- Cloud Storage (e.g., AWS S3, Google Cloud Storage)
- Streaming Data (e.g., IoT sensors, website user activity)
This data can be structured (tables, spreadsheets) or unstructured (text, images, videos). A good data pipeline should support multiple data formats and ensure smooth collection.
2. Processing Data
Once data is collected, it needs to be processed and transformed to make it usable. This step includes:
- Cleaning → Removing duplicate, missing, or incorrect data.
- Filtering → Selecting only relevant data for analysis.
- Aggregation → Combining multiple data points for meaningful insights.
- Normalization → Converting data into a consistent format.
For example, a company collecting sales data may need to remove errors, format date fields correctly, and convert currencies into a standard unit before using the data for reports.
3. Storing Data
After processing, the final step is storing data for future use. Data can be stored in:
- Data Warehouses (e.g., Snowflake, Google BigQuery) → Used for structured and analytical queries.
- Data Lakes (e.g., Amazon S3, Azure Data Lake) → Used for storing raw, unstructured data.
- Databases (e.g., PostgreSQL, MongoDB) → Used for operational and transactional data.
Proper storage ensures that data is easily accessible for reporting, machine learning, and business intelligence applications.
Tools Used to Build Data Pipelines
There are several tools available to help engineers build efficient data pipelines. Some popular tools include:
- Apache Kafka → A real-time data streaming platform.
- Apache Airflow → A workflow automation tool for scheduling and monitoring pipelines.
- AWS Glue → A serverless data integration tool.
- Google Cloud Dataflow → A data processing service for batch and real-time data.
- Fivetran → A tool that automates data integration from multiple sources.
- Talend → An open-source data integration tool for transforming and cleaning data.
These tools help automate data extraction, transformation, and loading (ETL), making data engineering more efficient.
Common Challenges in Data Pipelines
Building and maintaining data pipelines comes with its own set of challenges, such as:
- Data Quality Issues → Incomplete or inconsistent data can lead to incorrect insights.
- Scalability → As data volume grows, pipelines must be able to handle increased loads.
- Latency → Delays in data processing can affect real-time analytics.
- Security Risks → Sensitive data must be protected from unauthorized access.
These challenges can be addressed with proper data governance, monitoring, and optimization techniques.
Handling Large Data
As organizations collect more data, their pipelines must be designed to handle large-scale processing efficiently.
1. Ensuring Data Accuracy
Data accuracy is crucial for decision-making. Engineers must implement data validation techniques to detect and correct errors. Using checksums, anomaly detection, and validation rules, they can ensure data consistency.
2. Maintaining Security
Security is a major concern, especially when dealing with sensitive information. Best practices include:
- Data Encryption → Protecting data at rest and in transit.
- Access Control → Restricting who can access or modify data.
- Auditing → Keeping logs of data access and modifications.
By following these security practices, companies can prevent data breaches and ensure compliance with regulations like GDPR and HIPAA.
3. Steps to Build Your Own Data Pipeline
If you want to build a data pipeline, follow these steps:
- Identify Data Sources → Determine where the raw data comes from.
- Choose a Data Pipeline Tool → Select tools like Apache Airflow or AWS Glue.
- Define Data Processing Rules → Set up data cleaning, filtering, and transformation steps.
- Store the Processed Data → Choose a suitable database or data warehouse.
- Monitor and Optimize → Continuously check pipeline performance and fix errors.
Following these steps ensures a smooth and efficient data pipeline for your business needs.
Future of Data Pipelines
The future of data pipelines is automation and AI-driven optimization. As businesses generate more data, modern pipelines will need to:
- Support AI and Machine Learning → Automate data-driven decision-making.
- Handle Edge Computing → Process data closer to its source for faster insights.
- Ensure Zero Downtime → Minimize failures with self-healing capabilities.
With advancements in cloud computing and real-time analytics, data pipelines will become smarter, faster, and more scalable.
The Bottom Line
Data pipelines are essential for organizations that rely on data-driven insights. They automate the process of collecting, processing, and storing data, ensuring businesses have accurate and up-to-date information.
By using the right tools and best practices, companies can build efficient, secure, and scalable data pipelines that support real-time decision-making.
Whether you’re a beginner in data engineering or an experienced professional, understanding data pipelines is key to managing and optimizing large-scale data. Start building your pipeline today and unlock the true potential of your data!



